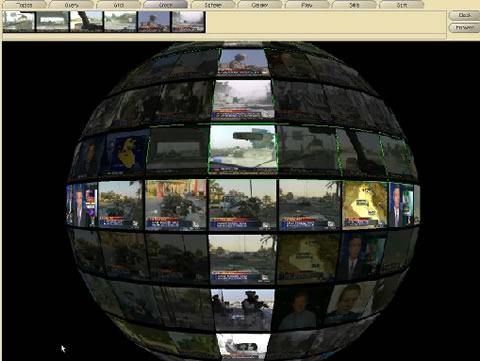
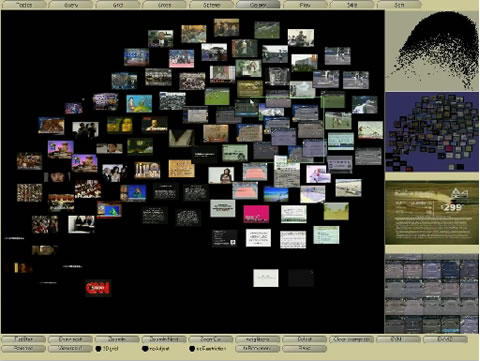
Sergi Mínguez en Juan Dürsteler hebben op 1 juni 2009 een interessant artikel over de verschillende visuele zoekmachines die er op dit moment zijn gepubliceerd in het online magazine infovis.net.
Uitgangspunt is er steeds meer verschillende soorten content zoals websites, afbeeldingen, videos, nieuws, boeken en multimedia beschikbaar is op het net maar dat de traditionele zoekmachines zoals Yahoo, Google of Microsoft dit onderscheid niet of te weinig ondersteunen. Ze brengen veranderen aan in de bestaande zoekomgeving maar nemen daardoor de bottlenecks in presentatie van de zoekresultaten uit het traditionele systeem over waardoor de interactie niet verbeterd. Als voorbeeld noemen ze Yahoo! Alpha website, Search Monkey website en de Google Universal Search. Een verandering hierin zou in het algemeen een goede impuls zijn voor de visualisatie en presentatie van gevonden informatie. De interactie van de gebruiker met de gevonden informatie zou daardoor enorm kunnen verbeteren.
Ze introduceren twee concepten (query intention, exploratory search) die ze als basis van hun stelling 'waarom zijn visuele zoekmachines nodig' gebruiken.
De zoekmachines die ze bekijken zijn:
• SearchMe website
• Yahoo! Alpha website
• Search Monkey website
• KartOO website
• Ujiko website
• Quintura website
• oSkope website
• Newsmap website
• Grokker


















![Roken04[1].gif](http://www.latebytes.nl/archives/2008/08/13/Roken04%5B1%5D.gif)