![Roken04[1].gif](http://www.latebytes.nl/archives/2008/08/13/Roken04%5B1%5D.gif) Om objecten te kunnen begrijpen en ordenen hebben ze namen nodig. Dit rookobject heet bijvoorbeeld een pijp en zou gecategoriseerd kunnen worden onder de verzamelnaam rookwaar. Om iets terug te kunnen vinden moeten deze naam opgenomen worden in een woordenlijst. Het liefst binnen boomstructuur waarbij zijn ouder dan bijvoorbeeld rookwaar zou kunnen heten.
Om objecten te kunnen begrijpen en ordenen hebben ze namen nodig. Dit rookobject heet bijvoorbeeld een pijp en zou gecategoriseerd kunnen worden onder de verzamelnaam rookwaar. Om iets terug te kunnen vinden moeten deze naam opgenomen worden in een woordenlijst. Het liefst binnen boomstructuur waarbij zijn ouder dan bijvoorbeeld rookwaar zou kunnen heten.
Mede dankzij enerzijds de opkomst van de multimedia waarbinnen bewegende beelden een steeds grotere rol spelen en anderzijds de mogelijkheid voor iedere internet gebruiker om zelf tekst en beeld te publiceren is het echter ondoenlijk om alle afzonderlijke beelden handmatig te labelen en in te delen. Het zou een te omvangrijke klus zijn, zeg maar gerust onmogelijk. Binnen een lap tekst kan er nog op de afzonderlijke woorden gezocht worden maar bij beeld is dit onmogelijk. Er is geen houvast aan tekst om toch een soort automatische analyse, indexering, ordening en ontsluiting te maken. Je ziet dan ook steeds meer initiatieven die hier oplossingen voor ontwikkelen. MediaMill bijvoorbeeld.
MediaMill, ontwikkeld binnen de universiteit van Amsterdam, is een semantische zoekmachine die gebaseerd op de nieuwste technologische ontwikkelingen dat al kan. Ze hebben op onder andere de gebieden van afbeelding en video verwerking, computer vision, taal- en spraaktechnologie, lerende machines and informatie visualisatie de grenzen opgezocht.
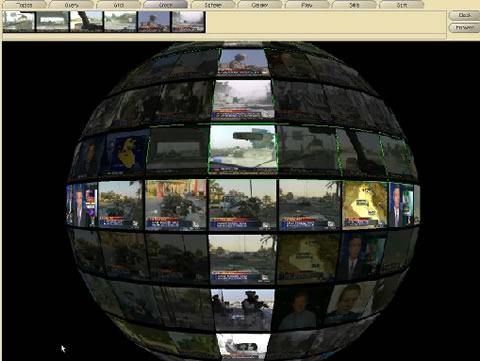
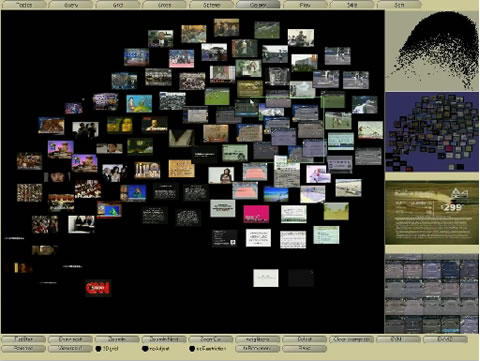
PDF met achtergrondinformatie
Concept-based Video Indexing and Retrieval (juli 2007)




















