Als programmeur gebruik je vaak fora en discussie omgevingen om oplossingen voor bepaalde vraagstukken te vinden. Waar iemand zich bevindt is dan niet van belang. Zolang er maar een internetverbinding mogelijk is. Toch is het ook handig om te weten of er mensen met dezelfde vaardigheden fysiek in je omgeving zijn. Voor bijvoorbeeld een Django sprint waar mensen met elkaar rond de tafel gaan zitten om gezamenlijk bugs op te lossen, functionaliteit uit te breiden of vertalingen te ontwikkelen met als doel om, in geval van Django, een framework te verbeteren.
Een geografische visualisatie van deze informatie is dan de manier om iemand inzicht te geven in wie zich in de buurt bevindt.
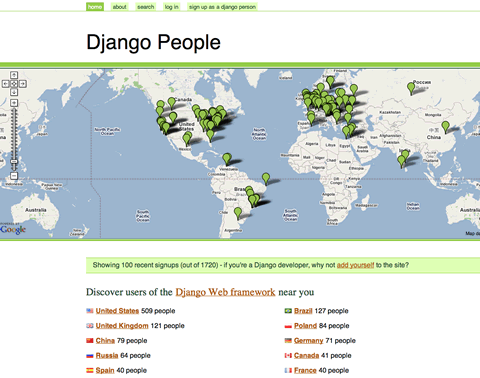
Continue reading De locatie van Django programmeurs.



















![Roken04[1].gif](http://www.latebytes.nl/archives/2008/08/13/Roken04%5B1%5D.gif)